【VBA】FindFirstFileW、FindNextFileWを使ってファイルリストを取得する(Unicode 文字 対応版、64bit版)
FindFirstFileW による Unicode対応してみた
以前の記事で、FindFirstFile を使って、ファイルリストを取得するコードを書いたが、Unicode文字が含まれると文字化けするため修正してみた。
処理としては、ざっくりいうと、FindFirstFileA、FindNextFileA を使用していたものを、FindFirstFileW、FindNextFileW に変えた + 64bit対応したものである。
z1000s.hatenablog.com
2GB超のファイルサイズを求める
ついでなので、2GBを超えるファイルサイズを求める方法も追加してある。
以下の部分です。
fd.nFileSizeLow、fd.nFileSizeHigh が Long なので、&H7FFFFFFF ( 2,147,483,647 ) を超えると負数となるため、それを補正する必要がある。
そこで、LongLong 型の &HFFFFFFFF^、&H7FFFFFFF^ と And を取って Long 型ではなく、LongLong 型にキャストして処理している。
ちなみに、CLngLngは、下図の通りなので却下。
Dim llFileSize As LongLong llFileSize = fd.nFileSizeLow And &HFFFFFFFF^ llFileSize = llFileSize + (fd.nFileSizeHigh And &H7FFFFFFF^) * &H100000000^

失敗
2GB超対応で最初に考えたのは、WIN32_FIND_DATAW の、nFileSizeHigh と nFileSizeLow を合わせて、「LongLong のメンバーにまとめてしまえばいいのでは?」と考えたが、VBA の構造体が 4Byte パックなので、LongLong のメンバーにするとその境界を跨ぐため、あっさりと失敗に終わった。
あとから気が付いたが、リトルエンディアンだから、nFileSizeHigh が先にある時点で駄目なんだろう。
Private Type WIN32_FIND_DATAW dwFileAttributes As Long ftCreationTime As FILETIME ftLastAccessTime As FILETIME ftLastWriteTime As FILETIME nFileSizeHigh As Long nFileSizeLow As Long dwReserved0 As Long dwReserved1 As Long cFileName(MAX_PATH * 2 - 1) As Byte cAlternateFileName(27) As Byte dwFileType As Long dwCreatorType As Long wFinderFlags As Integer End Type
【VBA】SafeArrayGetDim を使って、配列の次元数を求める
ネットを見ていると、SafeArrayGetDim のVBA での宣言は、以下のように書かれているのを見かける。
Private Declare PtrSafe Function SafeArrayGetDim Lib "oleaut32" (ByRef psa() As Any) As Long
しかし、MSのサイトの C++ 表記では、以下のようになっている。
UINT SafeArrayGetDim(
[in] SAFEARRAY *psa
);
引数は、SAFEARRAY を指すポインタであるので、今回の処理では、以下のようにして使っている。
(最初に書いた宣言で、配列を渡すと、意図した値は返ってこないようです。)
Private Declare PtrSafe Function SafeArrayGetDim Lib "oleaut32" (ByVal psa As LongPtr) As Long
実行結果

備考
SAFEARRAY を指すポインタが取得できれば、SAFEARRAY 関連のAPIを使って出来ることが増えるかもしれません。
こちらのサイトを参考にさせていただきました。
www5f.biglobe.ne.jp
別解
2022/9/29 追記
SAFEARRAY を指すポインタが取得できたら、SafeArrayGetDim を呼ばずに、SAFEARRAY 構造体の先頭メンバー cDims を取得してもよさそう。
Dim iDims As Integer 'SAFEARRAY 構造体の戦闘メンバー cDims を引っ張ってくる Call RtlMoveMemory(iDims, ByVal pArray, Len(iDims))
【C++】色を選択できるコンボボックス(ドロップダウンリスト)を作ってみた(MFC 未使用)
前置きが長いので、ソースが欲しい方は、リンクで前置きをスキップして下さいw
きっかけ
趣味のような感じで、VBAのコードを書いているのですが、VBEのデフォルトの色が今ひとつなので、VBEThemeColorEditor というツールを使ってカスタマイズした色に変更しています。
自分の好きな色にカスタマイズ出来るので重宝しているのですが、正直、使い勝手があまりよくありません。(個人の感想です。)
そこで、機能拡張版を自分で作ろうと動き始めました。
VBEの設定画面で、各項目ごとに色の割り振りをする機能も含めようと考えたのですが、そのためには、今回作成した「色を選択できるコンボボックス」が必要になったわけです。
でも、コンボボックスは、本来文字列を表示するだけのものなので、自分で作るしかないという結論に・・・


環境
2022/10/19 開発環境を変えて、コードを一部変更しました。
OS:Windows 10 Home 64bit Windows 11 Home 64bit
Microsoft Visual Studio Community 2019 Microsoft Visual Studio Community 2022
技術情報
Microsoft のサイトの翻訳ですwww
メッセージ
WM_INITDIALOG
ダイアログボックスが表示される直前にダイアログボックスプロシージャに送られます。ダイアログ ボックス プロシージャは通常、このメッセージを使用してコントロールを初期化したり、
ダイアログ ボックスの外観に影響を与えるその他の初期化タスクを実行したりします。
wParam
デフォルトのキーボードフォーカスを受け取るためのコントロールへのハンドル。ダイアログボックスのプロシージャが TRUE を返した場合にのみ、デフォルトのキーボードフォーカスが割り当てられます。
lParam
追加の初期化データ。このデータは、ダイアログボックスの作成に使用されるCreateDialogIndirectParam、CreateDialogParam、DialogBoxIndirectParam、またはDialogBoxParam関数の呼び出しでlParamパラメータとしてシステムに渡されます。プロパティシートの場合、このパラメータはページの作成に使用されるPROPSHEETPAGE構造体へのポインタです。他のダイアログボックス作成関数が使用されている場合、このパラメータは0です。
戻り値
ダイアログボックスのプロシージャは、キーボードフォーカスを wParam で指定されたコントロールに設定するようにシステムに指示するために TRUE を返します。そうでなければ、システムがデフォルトのキーボードフォーカスを設定しないようにするために FALSE を返すべきです。
WM_DRAWITEM
今回の肝となる部分です。オーナーが描いたボタン、コンボボックス、リストボックス、メニューの視覚的側面が変更された場合に、その親ウィンドウに送信されます。
wParam
WM_DRAWITEM メッセージを送信したコントロールの識別子を指定します。メッセージがメニューによって送信された場合、このパラメータは 0 です。
lParam
描画される項目と必要とされる描画の種類に関する情報を含む DRAWITEMSTRUCT 構造体へのポインタ。
戻り値
アプリケーションがこのメッセージを処理した場合は、TRUE を返すべきです。
備考
既定では、DefWindowProc 関数は、所有者が描画したリスト・ボックス項目のフォーカス矩形を描画します。
DRAWITEMSTRUCT 構造体の itemAction メンバは、アプリケーションが実行すべき描画操作を指定します。
このメッセージの処理から戻る前に、アプリケーションは、DRAWITEMSTRUCT構造体のhDCメンバによって識別されるデバイス・コンテキストがデフォルト状態にあることを確認する必要があります。
WM_COMMAND
ユーザーがメニューからコマンド項目を選択したとき、コントロールが親ウィンドウに通知メッセージを送信したとき、またはアクセラレータのキーストロークが変換されたときに送信されます。wParam
lParam
戻り値
アプリケーションがこのメッセージを処理した場合は、ゼロを返すべきです。
wParamとlParamのパラメータの使い方
| メッセージソース | wParam (High WORD) |
wParam (Low WORD) |
lParam |
|---|---|---|---|
| メニュー | 0 | メニュー識別子(IDM_*) | 0 |
| アクセラレータ | 1 | アクセラレータ識別子(IDM_*) | 0 |
| コントロール | コントロール定義の通知コード | コントロール識別子 | コントロールウィンドウへのハンドル |
構造体
オーナー・ウィンドウが、オーナーが描画したコントロールまたはメニュー項目の描画方法を決定するために使用する情報を提供します。
所有者が描画したコントロールまたはメニュー項目の所有者ウィンドウは、WM_DRAWITEM メッセージの lParam パラメータとしてこの構造体へのポインタを受け取ります。
typedef struct tagDRAWITEMSTRUCT { UINT CtlType; UINT CtlID; UINT itemID; UINT itemAction; UINT itemState; HWND hwndItem; HDC hDC; RECT rcItem; ULONG_PTR itemData; } DRAWITEMSTRUCT, *PDRAWITEMSTRUCT, *LPDRAWITEMSTRUCT;
CtlType
コントロールのタイプです。このメンバは、以下の値のいずれかになります。
| ODT_BUTTON | オーナードローボタン |
| ODT_COMBOBOX | オーナードローコンボボックス |
| ODT_LISTBOX | オーナードローリストボックス |
| ODT_LISTVIEW | リストビューコントロール |
| ODT_MENU | オーナードローメニュー |
| ODT_STATIC | オーナードロースタティックコントロール |
| ODT_TAB | タブコントロール |
CtlID
コンボボックス、リスト・ボックス、ボタン、または静的コントロールの識別子。
このメンバは、メニュー項目には使用されません。
itemID
メニュー項目のメニュー項目識別子、 またはリストボックスやコンボボックス内の項目のインデックス。
空のリストボックスやコンボボックスの場合、このメンバには -1 を指定することができます。
これにより、アプリケーションは、コントロール内にアイテムがなくても、rcItem メンバで指定された座標にのみフォーカスの矩形を描画することができます。
これは、リストボックスとコンボボックスのどちらにフォーカスがあるかをユーザに示します。itemAction メンバでどのようにビットを設定するかによって、リストボックスやコンボボックスがフォーカスを持っているかのように矩形を描画するかどうかが決まります。
itemAction
要求された描画アクション。このメンバは、1つ以上の値をとることができます。
| ODA_DRAWENTIRE | コントロール全体を描画する必要があります。 |
| ODA_FOCUS | コントロールはキーボードのフォーカスを失ったか、または獲得しました。itemState メンバをチェックして、コントロールがフォーカスを持っているかどうかを判断する必要があります。 |
| ODA_SELECT | 選択状態が変更されました。itemState メンバをチェックして、新しい選択状態を決定する必要があります。 |
itemState
現在の描画アクションが行われた後のアイテムの視覚的な状態。このメンバは、次の表に示す値の組み合わせとすることができる。
| ODS_CHECKED | メニュー項目にチェックを入れます。このビットはメニューでのみ使用されます。 |
| ODS_COMBOBOXEDIT | 描画は、オーナーが描画したコンボボックスの選択フィールド(編集コントロール)で行われます。 |
| ODS_DEFAULT | この項目はデフォルトの項目です。 |
| ODS_DISABLED | アイテムを無効にして描画します。 |
| ODS_FOCUS | アイテムにはキーボードフォーカスがあります。 |
| ODS_GRAYED | 項目をグレーにします。このビットはメニューでのみ使用されます。 |
| ODS_HOTLIGHT | アイテムがホットトラックされている、つまり、マウスがアイテムの上にあるときにアイテムがハイライトされます。 |
| ODS_INACTIVE | 項目は非アクティブであり、メニューに関連付けられたウィンドウは非アクティブです。 |
| ODS_NOACCEL | コントロールはキーボードアクセラレータの合図なしで描画されます。 |
| ODS_NOFOCUSRECT | コントロールはフォーカスインジケータのキューなしで描画されます。 |
| ODS_SELECTED | メニュー項目のステータスが選択されています。 |
hwndItem
コンボボックス、リスト・ボックス、ボタン、および静的コントロールの場合は、コントロールへのハンドルです。
メニューの場合、このメンバは、項目を含むメニューへのハンドルです。
hDC
このデバイスコンテキストは、コントロール上で描画操作を行う際に使用する必要があります。
rcItem
描画されるコントロールの境界を定義する矩形。
この矩形は、hDC メンバで指定されたデバイスコンテキストにあります。
コンボボックス、リストボックス、ボタンなどのデバイスコンテキストにオーナーウィンドウが描画するものは、システムが自動的にクリップしますが、メニュー項目はクリップしません。
メニュー項目を描画するとき、オーナー・ウィンドウは rcItem メンバで定義された矩形の境界外に描画してはいけません。
itemData
メニュー項目に関連付けられたアプリケーション定義の値。
コントロールの場合、このパラメータはLB_SETITEMDATAまたはCB_SETITEMDATAメッセージによってリストボックスまたはコンボボックスに最後に割り当てられた値を指定します。
リストボックスまたはコンボボックスがLBS_HASSTRINGSまたはCBS_HASSTRINGSスタイルを持っている場合、この値は最初はゼロです。
そうでなければ、この値は、以下のメッセージの1つのlParamパラメータでリストボックスまたはコンボボックスに渡された値が初期値となります。
- CB_ADDSTRING
- CB_INSERTSTRING
- LB_ADDSTRING
- LB_INSERTSTRING
ソース
おまけ
空のプロジェクトを作って、そこからコードを書いて、「さあビルド」となって、下記エラーが発生!!!
LNK2019 未解決の外部シンボル _main が関数 "int __cdecl invoke_main(void)" (?invoke_main@@YAHXZ) で参照されました
「は???」となったわけですよ。
でも、これは以前も経験していて、回避方法は覚えていた。(はずだった・・・)
空のプロジェクトを作ると、プロジェクトのプロパティは、デフォルトでコンソールアプリになっているので、それを直す。(Debug と Release の両方)
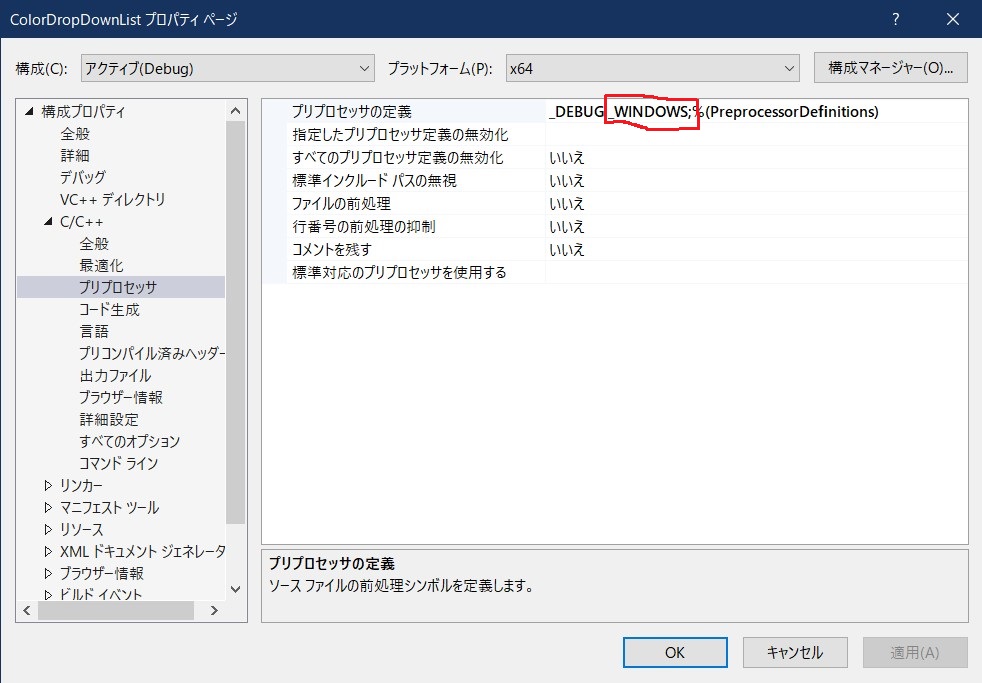
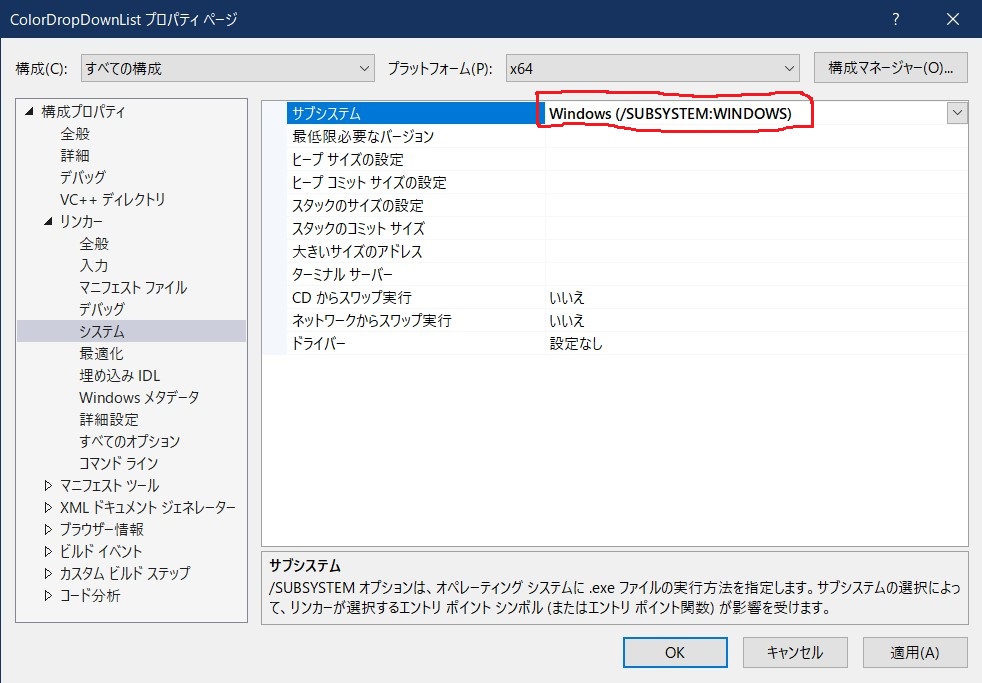
「これで、大丈夫」と再度ビルドしても、まだエラーが消えない。
あれこれイジっていて、気がついたのが、ソリューションプラットフォーム。
x86 になっている。これを x64 に直して・・・
無事解決しました。

【VBA】暗号化API を使って、ファイルのハッシュ値(SHA-1、SHA-256、SHA-512、MD5)を求めてみた。
ダウンロードしたファイルの検証や、ファイルの改竄がないかの検証などに
MD5や、SHA-256などによるハッシュ値が使われる事があります。
例えば、下の図は、CrystalDiskInfoのダウンロードサイト に記載されているハッシュ値部分をキャプチャしたものです。

今回、VBA で、ファイルをByte 配列に読み込んで、
MD5、SHA-1、SHA-256、SHA-512によるハッシュ値を求めてみました。
(MS が非推奨と言っているAPIを使っています。)
以下、非推奨とうたっている部分の抜粋と翻訳
This API is deprecated. New and existing software should start using Cryptography Next Generation APIs. Microsoft may remove this API in future releases.
この API は非推奨です。新規および既存のソフトウェアは、Cryptography Next Generation APIs の使用を開始する必要があります。Microsoft は将来のリリースでこの API を削除する可能性があります。
暗号学的ハッシュ関数
暗号学的ハッシュ関数は、ハッシュ関数のうち、暗号など情報セキュリティの用途に適する暗号数理的性質をもつもの。任意の長さの入力を(通常は)固定長の出力に変換する
https://ja.wikipedia.org/wiki/%E6%9A%97%E5%8F%B7%E5%AD%A6%E7%9A%84%E3%83%8F%E3%83%83%E3%82%B7%E3%83%A5%E9%96%A2%E6%95%B0
SHA-1
Secure Hash Algorithmシリーズの暗号学的ハッシュ関数で、SHAの最初のバージョンであるSHA-0の弱点を修正したものだそうです。
Wikipediaによると、「シャーワン」と読むらしいです。
ja.wikipedia.org
SHA-2
前身のSHA-1から多くの改良が加えられており、6つのバリエーションが存在し、
SHA-256、SHA-512は、そのバリエーションのひとつです。
ja.wikipedia.org
MD5
MD4が前身であり、安全性を向上させたものとされている。
ただし、
2018年現在において、弱点が発見されていることを筆頭に暗号学的ハッシュ関数として必要な強度は既に残っていないので、強度が必要な場合には使ってはいけない。
https://ja.wikipedia.org/wiki/MD5#%E7%94%A8%E9%80%94
コード
ライセンス
MITライセンスを適用するものとします。
ご自由にお使いください。
Copyright (c) 2020 Z1000R_LR
This software is released under the MIT License.
http://opensource.org/licenses/mit-license.php
API 宣言等
Public Enum ALG_ID CALG_MD5 = &H8003& CALG_SHA1 = &H8004& CALG_SHA_256 = &H800C& CALG_SHA_512 = &H800E& End Enum Private Declare PtrSafe Function CryptAcquireContext Lib "Advapi32.dll" Alias "CryptAcquireContextA" ( _ ByRef phProv As LongPtr, _ ByVal szContainer As String, _ ByVal szProvider As String, _ ByVal dwProvType As Long, _ ByVal dwFlags As Long) As Long Private Declare PtrSafe Function CryptCreateHash Lib "Advapi32.dll" ( _ ByVal hProv As LongPtr, _ ByVal algid As Long, _ ByVal hKey As LongPtr, _ ByVal dwFlags As Long, _ ByRef phHash As LongPtr) As Long Private Declare PtrSafe Function CryptHashData Lib "Advapi32.dll" ( _ ByVal hHash As LongPtr, _ ByRef pbData As Any, _ ByVal dwDataLen As Long, _ ByVal dwFlags As Long) As Long Private Declare PtrSafe Function CryptGetHashParam Lib "Advapi32.dll" ( _ ByVal hHash As LongPtr, _ ByVal dwParam As Long, _ ByRef pbData As Any, _ ByRef pdwDataLen As Long, _ ByVal dwFlags As Long) As Long Private Declare PtrSafe Function CryptDestroyHash Lib "Advapi32.dll" ( _ ByVal hHash As LongPtr) As Long Private Declare PtrSafe Function CryptReleaseContext Lib "Advapi32.dll" ( _ ByVal hProv As LongPtr, _ ByVal dwFlags As Long) As Long Private Declare PtrSafe Function GetLastError Lib "kernel32" () As Long Private Const PROV_RSA_AES As Long = &H18& Private Const CRYPT_VERIFYCONTEXT As Long = &HF0000000 Private Const HP_HASHVAL As Long = &H2& Private Const ERROR_FILE_NOT_FOUND As Long = &H2& Private Const ERROR_INVALID_DATA As Long = &HD&
ハッシュ値計算
'パラメータ ' byContentArry(IN) :ハッシュを計算するファイル(Byte配列) ' algid(IN) :取得するハッシュの種類 ' sHash(OUT) :計算したハッシュ値 '復帰値 ' 0 :成功 ' 0以外 :失敗(GetLastErrorによるエラーコード) Public Function getHash(ByRef byContentArry() As Byte, ByVal algid As ALG_ID, ByRef sHash As String) As Long Dim byHash() As Byte Dim hProv As LongPtr Dim hHash As LongPtr Dim lHashBytes As Long Dim lResult As Long Dim lContentBytes As Long Dim i As Long sHash = "" 'ハッシュ長設定 Select Case algid Case ALG_ID.CALG_MD5 lHashBytes = 16 Case ALG_ID.CALG_SHA1 lHashBytes = 20 Case ALG_ID.CALG_SHA_256 lHashBytes = 32 Case ALG_ID.CALG_SHA_512 lHashBytes = 64 Case Else Err.Raise ERROR_INVALID_DATA, "getHash", "Invalid ALG_ID.[ 0x" & Right$("0000000" & Hex(algid), 8) & " ]" End Select 'ハッシュ格納用 ReDim byHash(lHashBytes - 1) Do '暗号化サービスプロバイダ内の特定のキーコンテナのハンドルを取得 lResult = CryptAcquireContext(hProv, vbNullString, vbNullString, PROV_RSA_AES, CRYPT_VERIFYCONTEXT) If lResult = 0 Then lResult = GetLastError Exit Do End If '暗号化サービスプロバイダのハッシュオブジェクトのハンドル作成 lResult = CryptCreateHash(hProv, algid, 0, 0, hHash) If lResult = 0 Then lResult = GetLastError Exit Do End If 'ハッシュオブジェクトにデータを追加 lContentBytes = UBound(byContentArry) - LBound(byContentArry) + 1 lResult = CryptHashData(hHash, byContentArry(0), lContentBytes, 0) If lResult = 0 Then lResult = GetLastError Exit Do End If 'ハッシュ値取得 lResult = CryptGetHashParam(hHash, HP_HASHVAL, byHash(0), lHashBytes, 0) If lResult = 0 Then lResult = GetLastError Exit Do End If 'Byte配列から16進文字列化 sHash = String$(lHashBytes * 2, "0") For i = 0 To lHashBytes - 1 Mid$(sHash, i * 2 + 1, 2) = Right$("0" & Hex(byHash(i)), 2) Next i Loop While False If hHash <> 0 Then 'hHashで参照されるハッシュオブジェクト破棄 Call CryptDestroyHash(hHash) End If If hProv <> 0 Then '暗号サービスプロバイダと鍵コンテナのハンドル解放 Call CryptReleaseContext(hProv, 0) End If End Function
ファイル読み込み
Public Function getFileContent(ByVal sTargetPath As String, ByRef byContentArry() As Byte) As Long Dim iFileNo As Integer Dim lBytes As Long On Error GoTo ERR_FILE_OPEN_FAIL 'ファイルパスチェック If Len(sTargetPath) = 0 Then Err.Raise ERROR_INVALID_DATA, "getFileContent", "Path is zero length." ElseIf Dir(sTargetPath) = "" Then Err.Raise ERROR_FILE_NOT_FOUND, "getFileContent", "File Not Found." ElseIf GetAttr(sTargetPath) = vbDirectory Then Err.Raise ERROR_INVALID_DATA, "getFileContent", "Path is directory." End If 'ファイル読み込み iFileNo = FreeFile Open sTargetPath For Binary Access Read As iFileNo lBytes = LOF(iFileNo) ReDim byContentArry(lBytes - 1) Get iFileNo, 1, byContentArry Close iFileNo Exit Function ERR_FILE_OPEN_FAIL: getFileContent = Err.Number Debug.Print "[0x" & Right$("0000000" & Hex(Err.Number), 8) & "] getFileContent :" & Err.Description End Function
実行例
呼び出し
Public Sub getVBE7DllHash() Const TARGET_PATH As String = "C:\Program Files\Microsoft Office\root\vfs\ProgramFilesCommonX64\Microsoft Shared\VBA\VBA7.1\VBE7.DLL" Dim byContentArry() As Byte Dim sHash As String Call getFileContent(TARGET_PATH, byContentArry) Call getHash(byContentArry, CALG_MD5, sHash) Debug.Print "MD5 :" & sHash Call getHash(byContentArry, CALG_SHA1, sHash) Debug.Print "SHA1 :" & sHash Call getHash(byContentArry, CALG_SHA_256, sHash) Debug.Print "SHA-256:" & sHash Call getHash(byContentArry, CALG_SHA_512, sHash) Debug.Print "SHA-512:" & sHash End Sub
実行結果

注)VBEThemeColorEditorで、色をカスタマイズしたVBE7.DLLのため、正規のVBE7.DLL のハッシュ値とは異なります。

【VBA】トライ木を使って、文字列Aにある文字列Bを数えてみた
トライ木とは
人に説明できるだけ理解していないので、Wikipediaより抜粋。
順序付き木の一種。あるノードの配下の全ノードは、自身に対応する文字列に共通するプレフィックス(接頭部)があり、ルート(根)には空の文字列が対応している。値は一般に全ノードに対応して存在するわけではなく、末端ノードや一部の中間ノードだけがキーに対応した値を格納している。2分探索木と異なり、各ノードに個々のキーが格納されるのではなく、木構造上のノードの位置とキーが対応している。
https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%A9%E3%82%A4_(%E3%83%87%E3%83%BC%E3%82%BF%E6%A7%8B%E9%80%A0)
コード
トライ木
クラスモジュール:CTrie
Option Explicit Private Const BASE As Long = 65& Public val As Long Private nxt_(25) As CTrie Public Property Get nxt(ByVal index As Long) As CTrie Set nxt = nxt_(index) End Property Public Function createNxt(ByVal index As Long) As CTrie Set nxt_(index) = New CTrie Set createNxt = nxt_(index) End Function Public Sub instert(ByVal s As String) Dim cur As CTrie Dim i As Long Set cur = Me For i = 1 To Len(s) If cur.nxt(Asc(Mid(s, i, 1)) - BASE) Is Nothing Then Call cur.createNxt(Asc(Mid(s, i, 1)) - BASE) End If Set cur = cur.nxt(Asc(Mid(s, i, 1)) - BASE) Next i cur.val = cur.val + 1 End Sub Public Function exitsIn(ByVal s As String) As Boolean Dim cur As CTrie Dim ss As String Dim i As Long For i = 1 To Len(s) Set cur = Me ss = Mid(s, i) Do While Len(ss) > 0 And (Not cur Is Nothing) Set cur = cur.nxt(Asc(Left(ss, 1)) - BASE) If Not cur Is Nothing Then If cur.val > 0 Then exitsIn = True Exit Function End If End If If Len(ss) < 2 Then Exit Do End If ss = Mid(ss, 2) Loop Next i exitsIn = False End Function Public Function count(ByVal s As String) As Long Dim cur As CTrie Dim lCount As Long Dim ss As String Dim i As Long For i = 1 To Len(s) Set cur = Me ss = Mid(s, i) Do While Len(ss) > 0 And (Not cur Is Nothing) Set cur = cur.nxt(Asc(Left(ss, 1)) - BASE) If Not cur Is Nothing Then lCount = lCount + cur.val End If If Len(ss) < 2 Then Exit Do End If ss = Mid(ss, 2) Loop Next i count = lCount End Function
標準モジュール(クラスモジュールの呼び出し)
Sub fuga() Dim tr As CTrie Dim sPath As String Dim iFNo As Integer Dim s As String Dim ss As String Dim cnt As Long Dim i As Long Dim sw As New CStopWatch Dim start As LongLong Dim stp As LongLong start = sw.GetValueOfTickCnt sPath = "C:\Datas\sample.txt" iFNo = FreeFile Open sPath For Input Access Read As iFNo Line Input #iFNo, s Line Input #iFNo, ss cnt = CLng(ss) Set tr = New CTrie For i = 0 To cnt - 1 Line Input #iFNo, ss tr.instert ss Next i Close iFNo Debug.Print "Trie" Debug.Print "Result:" & tr.count(s) stp = sw.GetValueOfTickCnt Debug.Print "Time :" & stp - start & " [msec]" End Sub
InStr
Sub piyo() Dim sPath As String Dim iFNo As Integer Dim s As String Dim ss As String Dim cnt As Long Dim c() As String Dim pos As Long Dim lResult As Long Dim i As Long Dim sw As New CStopWatch Dim start As LongLong Dim stp As LongLong start = sw.GetValueOfTickCnt sPath = "C:\Datas\sample.txt" iFNo = FreeFile Open sPath For Input Access Read As iFNo Line Input #iFNo, s Line Input #iFNo, ss cnt = CLng(ss) ReDim c(cnt - 1) For i = 0 To cnt - 1 Line Input #iFNo, ss c(i) = ss Next i Close iFNo For i = 0 To cnt - 1 pos = 1 Do pos = InStr(pos, s, c(i)) If pos > 0 Then lResult = lResult + 1 pos = pos + 1 End If Loop Until pos = 0 Next i stp = sw.GetValueOfTickCnt Debug.Print "Instr" Debug.Print "Result:" & lResult Debug.Print "Time :" & stp - start & " [msec]" End Sub
Sub hoge() Dim i As Long For i = 1 To 10 Call fuga Call piyo Next i End Sub
結果
テストデータ
yukicoder の、No.430 文字列検索 のテストデータ より、challege02.txt を使用してみた。
文字数:50,000
検索対象文字:5,000個(ランダム文字列)
こんな感じ(一部のみ)

5000の上が、検索元となるデータ文字列
5000の下が、検索文字列
結果
hoge の実行結果、トライ木は、InStr の約2倍の時間がかかりました。
トライ木が、InStrの約3割程度の時間で処理できた。
個人的には、トライ木が速いというよりも、
InStr が、予想以上に速かったという感想。
コメントによるご指摘により、計測位置が間違っている事が判明したため、下記のデータを含めて修正しました。(2020/11/4 16:30)
| Trie木 | InStr | |
|---|---|---|
| 1 | 547 | 250 |
| 2 | 547 | 265 |
| 3 | 547 | 281 |
| 4 | 562 | 265 |
| 5 | 516 | 281 |
| 6 | 500 | 281 |
| 7 | 500 | 265 |
| 8 | 532 | 266 |
| 9 | 484 | 265 |
| 10 | 500 | 266 |
| 平均 [msec] | 523 | 268 |

ちなみに、C++で実装したら、6 msec でした。
【C++】Windowsをシャットダウン or サスペンド させる
スタートメニューを辿っていくのが面倒だったので、
実行ファイルを作って、デスクトップにショートカットを作ることにしました。
環境
Windows 10 Home 64bit
Visual Studio Community 2019
#include <Windows.h> #include <iostream> using namespace std; BOOL EnablePrivileges(LPCTSTR lpcPrivilegeName, BOOL bEnable); int main() { int iResult{ 1 }; wstring sResult; while (true) { //SE_SHUTDOWN_NAME(シャットダウン特権) を有効にする if (!EnablePrivileges(SE_SHUTDOWN_NAME, TRUE)) { sResult = L"EnablePrivileges failed"; break; } if (!InitiateSystemShutdownEx(nullptr, nullptr, 0, FALSE, FALSE, SHTDN_REASON_FLAG_USER_DEFINED)) { sResult = L"InitiateSystemShutdownEx failed"; break; } sResult = L"InitiateSystemShutdownEx succeeded !"; iResult = 0; break; } wcout << sResult << endl; return iResult; } BOOL EnablePrivileges(LPCTSTR lpcPrivilegeName, BOOL isEnable) { //プロセストークン取得 HANDLE hToken; BOOL isSuccess = OpenProcessToken(GetCurrentProcess(), TOKEN_ADJUST_PRIVILEGES | TOKEN_QUERY, &hToken); if (!isSuccess) { return FALSE; } //特権に対応するLUID取得 LUID luid; isSuccess = LookupPrivilegeValue(nullptr, lpcPrivilegeName, &luid); if (isSuccess) { //TOKEN_PRIVILEGES型のオブジェクトに、LUIDと特権の属性(有効にするか無効にするか)を指定 TOKEN_PRIVILEGES tokenPrivileges; tokenPrivileges.PrivilegeCount = 1; tokenPrivileges.Privileges[0].Luid = luid; tokenPrivileges.Privileges[0].Attributes = isEnable ? SE_PRIVILEGE_ENABLED : 0; //特権を設定する isSuccess = AdjustTokenPrivileges(hToken, FALSE, &tokenPrivileges, 0, 0, 0); } CloseHandle(hToken); return isSuccess; }
シャットダウンではなく、サスペンドさせたい場合には、
1.以下を追加
#include <powrprof.h> //SetSuspendState #pragma comment(lib, "PowrProf.lib")
2.以下を変更
//if (!InitiateSystemShutdownExW(nullptr, nullptr, 0, FALSE, FALSE, SHTDN_REASON_FLAG_USER_DEFINED)) if (!SetSuspendState(TRUE, FALSE, TRUE))
コメントは、適宜変更してください。
この実行ファイルでサスペンドさせると、復帰した時に、スタートメニューが表示されないので、スッキリしています。
【C++】フォルダ内のファイル一覧取得(エクスプローラー風ソート)
コード
#include <iostream> #include <vector> #include <algorithm> #include <string> #include <Windows.h> #include <shlwapi.h> //StrCmpLogicalW #pragma comment(lib,"Shlwapi.lib") using namespace std; int main() { //wcin の文字化け対策 ios_base::sync_with_stdio(false); wcin.imbue(locale("japanese")); wcout << L"Input target Folder:"; wstring sTargetFolder; getline(wcin, sTargetFolder); if (!sTargetFolder.size()) { wcout << L"Not entered.\n"; return 0; } //スペース等を含んだパスのような場合の前後のダブルクォーテーションを除去 if ((sTargetFolder.substr(0, 1) == L"\"") && (sTargetFolder.substr(sTargetFolder.size() - 1, 1) == L"\"")) sTargetFolder = sTargetFolder.substr(1, sTargetFolder.size() - 2); //パスの末尾が "\" でない場合、"\" を付加 if (sTargetFolder.substr(sTargetFolder.size() - 1) != L"\\") sTargetFolder += L"\\"; //全ファイルを対象 sTargetFolder += L"*"; WIN32_FIND_DATA fd; HANDLE hFind = FindFirstFileExW( sTargetFolder.c_str(), FindExInfoBasic, &fd, FindExSearchNameMatch, nullptr, FIND_FIRST_EX_LARGE_FETCH); if (hFind == INVALID_HANDLE_VALUE) { wcout << L"Target not found.\n"; return 0; } vector<wstring> vFiles; do { //フォルダは除外 if (fd.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY) continue; vFiles.push_back(fd.cFileName); } while (FindNextFileW(hFind, &fd)); FindClose(hFind); //エクスプローラー風のソート sort(vFiles.begin(), vFiles.end(), [](const wstring& ws1, const wstring& ws2) { return StrCmpLogicalW(ws1.c_str(), ws2.c_str()) < 0; }); for (const auto& v : vFiles) wcout << v << L"\n"; return 0; }
実行結果
検索対象ファイル

実行

通常のソートを使用した場合
sort(vFiles.begin(), vFiles.end());

気が向いたら、再帰して、サブフォルダも処理するやつを作るかもしれない・・・
(作りそうな気がする・・・)
参考
VBAで、FindFirstFile (Ex でないやつ)を使ったやつ
z1000s.hatenablog.com
上の記事ので紹介している記事の発展版。
VBAで、FindFirstFileEx を使ってやってるので、興味がある方はどうぞ。
www.excel-chunchun.com
sort を参考に(パクリとも言う)させていただきました。m(_ _)m
suzulang.com