【VBA】UTF-8 CSV の読み込みを、ADODB.Recordset と ADODB.Stream で比べてみた・・・第2回 ADODB.Streamを使ったコードの処理速度改善
前回のコードでは、完敗だったADODB.Stream ですが、汚名返上なるか?
見つけたサイトに掲載された方法による効果を検証してみます。
目次
前回の結果概要
不明な点
- ADODB.Stream があまりにも遅く、その原因が不明。
- 2回以上処理を繰り返すと、1回目に比べ、2回目以降がさらに遅くなる。
ADODB.Stream を使った処理の分析と改善
参考サイトの説明
参考としたサイトは、
www.mussyu1204.com
説明によると、「後ろの行ほどその行を取得するための時間が長くなっていく」
ことが原因とのこと。
今回のコードで、どの程度の変化があるのかを確認してみる。
1万行あたりの読み込み時間
1万行処理毎に開始からの経過時間を出力し、その差から1万行あたりの処理時間を求めてグラフにしてみた。

リンク先のサイトの説明にあるように
行が進むにつれて、読み込みに要する時間が増加していくのが確認できる。
それ以外にも
- 2回目以降は、6~7万件を超えるあたりから、1回目よりも遅いことも確認できる。
- 2回目と3回目は同じような傾向にあり、その差は小さい。
といった事がわかる。
注)
改善策
リンク先サイトに書かれている方法
指定した文字数を読み込み、その中から行データを切り出すという方法をとっている。ただし、リンク先のコードは、改行コードがCRLFなので、今回のデータの場合にはLFに変更する必要がある。
実行結果
1回に読み込む文字数を、512~16,382文字の範囲で変えて、それぞれの場合の時間を計測してみた。結果として、1回で読み込む文字数を増やしていくと、
- 読み込み時間が短くなっていくことが確認できる。
- 1回目と2回目以降の差が小さくなっていくことが確認できる。
まとまった文字数の読み込みが、効果があることが確認できた。
全データの読み込みにかかった時間は、以下の通り。
大幅に改善されている。
| 1回で読み込む文字数 | 時間(秒) | |
|---|---|---|
| Split 有 | Split 無 | |
| 512 | 37.63 | 29.51 |
| 1024 | 15.53 | 8.64 |
| 2048 | 15.32 | 8.60 |
| 4096 | 10.92 | 4.16 |
| 8192 | 10.55 | 3.77 |
| 16384 | 10.24 | 3.45 |
| 1行(1回目) | 145.61 | 134.88 |
| 1行(2回目) | 353.99 | 340.79 |
読み込み文字数別
縦軸のスケールが、グラフによって異なるので注意。


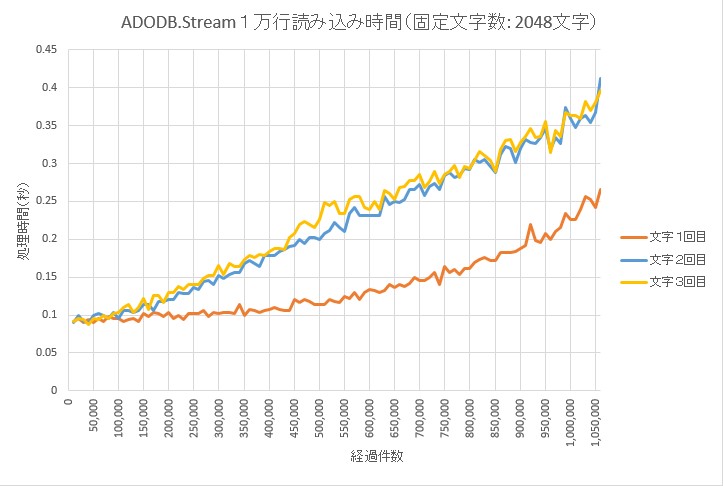
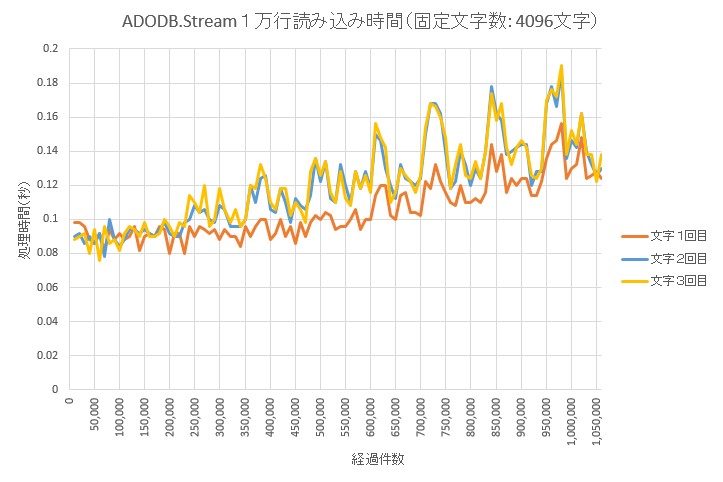
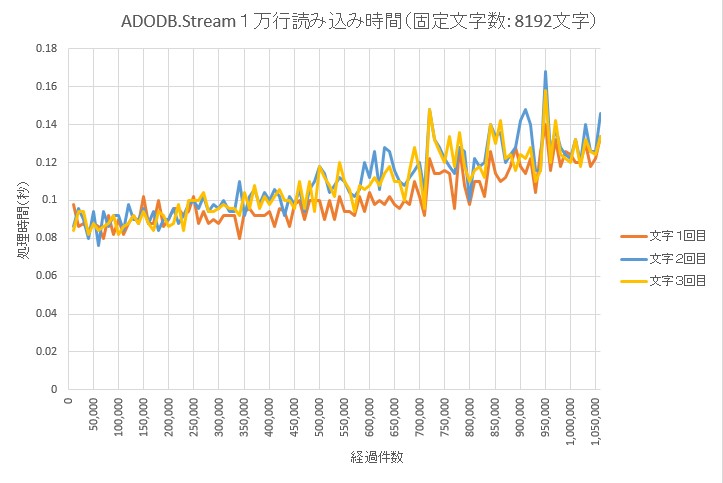

読み込み回別



文字数固定読み込みのコード
ADODB.Stream の ReadText メソッドに渡すパラメータに、読み込む文字数を指定するとで、必要な文字数の読み込みができる。今回のコードでは、定数 READ_CHAR_NUM に読み込む文字数を設定して、1回あたりの読み込み文字数を変えている。
ADODB.Recordset との比較
ADODB.Recordset の読み込み速度
ADODB.Stream と同様に、1万件毎の読み込み時間を計測してみた。その結果、
- ADODB.Recordset を使用した場合、読み込み行数に対する依存は確認できない。
- 1万行あたりの読み込み時間は、カーソルロケーションをClient とした場合が、最速であった。

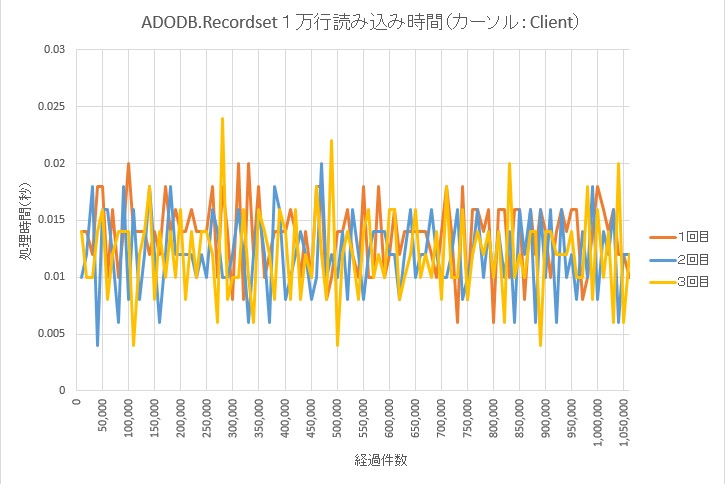
ADODB.Recordset と、ADODB.Stream の比較
ADODB.Recordset と ADODB.Stream(1回目)の比較
ADODB.Recordset の方が速い事は変わらないが、ADODB.Stream でも、条件によって、それに迫る結果を出すことが出来ている。
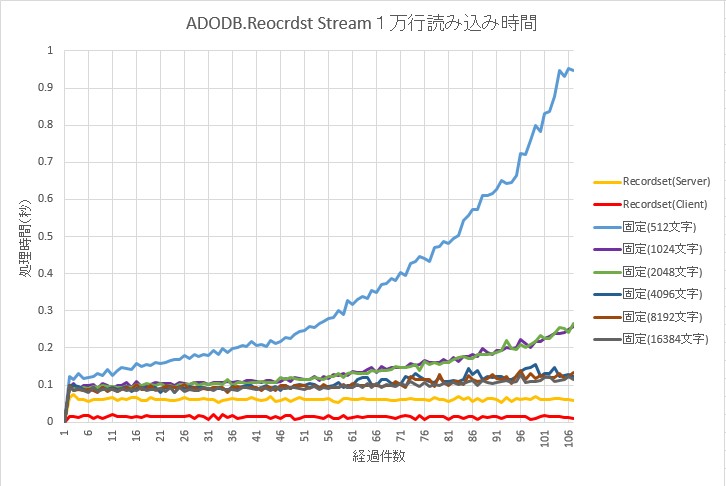
感想、考察
ファイル後半の行ほど、読み込みが遅い事に関して
あくまでも推測なのだが、ADODB.Stream の読み込みは、
読み込みするポインタ位置を、毎回ファイル先頭から探しているような印象がある。
そのため、
「1行毎に読み込むから遅い」
のではなく、
「(行単位であろうと、文字数単位であろうと)読み込みを行った回数が多くなるほど遅くなる」
となっているというのが実情なのではないかと思っている。
2回目が1回目より遅い事に関して
原因は不明。
Microsoft 公式によるClose メソッドの説明より抜粋
同サイトの日本語翻訳がおかしいので、英語のままで。
Use the Close method to close a Connection, a Record, a Recordset, or a Stream object to free any associated system resources. Closing an object does not remove it from memory; you can change its property settings and open it again later. To completely eliminate an object from memory, close the object and then set the object variable to Nothing (in Visual Basic).
https://docs.microsoft.com/ja-jp/sql/ado/reference/ado-api/close-method-ado?view=sql-server-ver15
Googleさんに翻訳してもらうと、こんな感じ。
Closeメソッドを使用して、Connection、Record、Recordset、またはStreamオブジェクトを閉じ、関連するシステムリソースを解放します。オブジェクトを閉じても、メモリからは削除されません。プロパティ設定を変更して、後で再度開くことができます。オブジェクトをメモリから完全に削除するには、オブジェクトを閉じてから、オブジェクト変数を(Visual Basicで)Nothingに設定します。
こう書かれてはいるが、Colse 後に、Nothing を設定しても、メモリ上に残っているような感じを受けた。
1回目の処理でゴミが残っていて、そのまま2回目を行うと、1回目のような結果を出せていないように思える。
実際に、1回目終了後、そのまま30分放置し、再度同じ処理を走らせても、結果は1回目直後に実施した場合との違いは認められなかった。
その直後に、Excel を終了させ、再度 Excel を立ち上げて、同じプロシージャを走らせると1回目のパフォーマンスが出ている。
ADODB.Stream 変数に対し、Nothing を設定しても、開放処理がきちんと行われていないような気がする。
もし本当にそうなのであれば、VBAのコードでは対処のしようがない。
ADODB.Recordset のカーソルロケーションが Client の場合、1万行あたりの読み込み速度と総読み込み時間がアンマッチな理由
カーソルロケーションを Client に設定した時が、1万行あたりの読み込み速度が1番速かったが、最終的な読み込み完了までの時間は、Server に設定した場合よりも遅くなっている。
これは、カーソルロケーションによって内部の処理の内容が変わることが変わることが原因で、間違っているわけではない。
サーバ側データのスナップショットコピーがクライアント側の Recordset オブジェクト内に一括して取り出されます。
https://blogs.msdn.microsoft.com/nakama/2008/10/16/ado/
上の記事内には書かなかったが、処理を開始してから先頭のレコードの読み込みを開始するまでに要する時間の差が非常に大きいため、このような現象が起こっている。
| カーソルロケーション | 先頭のレコード 読み込み開始までの所要時間(秒) |
|---|---|
| Server | 0.47 |
| Client | 23.00 |
このため、読み込むレコード数によってカーソルロケーションを選ばないと、よいレスポンスが得られない。
通常は、Client 側で良いと思うが、ある程度以上のレコード数があり、速度が出ない場合には、Server 側で試してみると改善する場合があるかもしれない。
まとめ
不明な点として上げた現象の根本的な原因は不明。
ただし、改善策として、今回のコードの有効性は確認できた。
- ADODB.Stream を使用する場合
- 読み込むデータ量が多く、速度が出ない場合には、面倒でも1行ずつではなく、ある程度まとまった文字数を読み込み、都度改行コードで分割して処理したほうがよい。
- その場合、1回に読み込む文字数が少ないと速度が出ない。
- 1行ずつ読み込みを行う場合は、データ量が少ない場合に限定したほうがよい。
- 改行コードが、CRLF以外の場合は、コード内で指定が必要
- 自分で区切り文字に応じた分解処理が必要
- ADODB.Recordset を使用する場合
- レコード数が少なければ、カーソルロケーションを Client、多ければ、Server に設定。
- Schema.ini が原則必要(文字セット、ヘッダ有無、区切り文字等。必要であれば各フィールド情報)
- 区切り文字に応じた分解処理は不要であるが、自分の意図した分割がされない場合には、Schema.ini の内容見直しが必要になる場合があるかもしれない。
- Recordset からのデータ取り出し時、Null 対応が必要な場合がある。(( ゚д゚) そんなの何処に出てきた?)
今回は、CSVの読み込みとしたが、実際には、CSVに限らず、プレーンテキストの場合でも同様のことが起こる事が考えられる。
その場合にもおそらく有効に使えそうな気がする。
【VBA】UTF-8 CSV の読み込みを、ADODB.Recordset と ADODB.Stream で比べてみた・・・第1回 1行ずつ読み込みしてみる
初めに
以前、ADODB.Recordset を使って、CSV の読み込みについてまとめたのだけれど、
世間一般では、UTF-8 のCSVに限って言えば、ADODB.Stream を使うのがメジャーなようです。
というか、「ADODB.Recordset の記事あるの?」って感じです。
自分が紹介した ADODB.Recordset による方法のマイナー感が拭えなくて、ちょっと悔しかったこともあり、2つを比べてみました。
また、後からまとめていた際に、分かってきたこともあり、追加調査分も含めて2回に分けて書いていこうと思います。
データ
まずは、使うデータ。
自分で作るのは面倒なので、公開されているものを探したら
以下のサイトが見つかったので、使わせてもらうことにした。
使ったのは、その中の東京のデータ(13_tokyo_all_20190930.csv)
ADODB.Streamを使う場合には改行コードが、CRLFではないので、指定が必要です。
先頭2行抜粋したのが以下
1,1000011000005,01,1,2018-04-02,2015-10-05,"国立国会図書館",,101,"東京都","千代田区","永田町1丁目10-1",,13,101,1000014,,,,,,,2015-10-05,1,"National Diet Library","Tokyo","1-10-1,Nagatacho, Chiyoda ku",,"コクリツコッカイトショカン",0 2,1000012010003,01,1,2018-04-02,2015-10-05,"内閣法制局",,101,"東京都","千代田区","霞が関3丁目1-1中央合同庁舎第4号館",,13,101,1000013,,,,,,,2015-10-05,1,"Cabinet Legislation Bureau","Tokyo","3-1-1,Kasumigaseki, Chiyoda ku",,"ナイカクホウセイキョク",0
ダウンロード元
t.co
処理概要
ADODB.Recordset
ADODBでデータベースに接続する場合と同様の処理です。
接続文字列を設定して、SQL発行して、Recordset を取得し、EOFまでループします。
ADODB.Stream
一般的に公開されているサンプルと同様の処理です。
Stream を開いて、LoadFromFile でロードして、
ReadText(adReadLine)で1行ずつ読み込み、Splitして、
EOFまでループします。
コード
共通部分
Option Explicit Private Const TARGET_FOLDER As String = "C:\Datas\CSV\法人情報\" Private Const TARGET_NAME As String = "13_tokyo_all_20190930.csv"
ADODB.Recordset
Public Sub readByAdoRecordset() Dim cn As ADODB.Connection Dim cmd As ADODB.Command Dim rs As ADODB.Recordset Dim lRecords As Long Dim i As Long Dim sgStart As Single Dim sgStop As Single Dim v As Variant sgStart = Timer On Error GoTo ERR_EXIT Set cn = New ADODB.Connection cn.Open "Provider=Microsoft.ACE.OLEDB.12.0;" _ & "Data Source=" & TARGET_FOLDER & ";" _ & "Extended Properties=""Text;" _ & "HDR=No;" _ & "FMT=Delimited""" Set cmd = New ADODB.Command Set cmd.ActiveConnection = cn cmd.CommandType = adCmdText cmd.CommandText = "SELECT * FROM [" & TARGET_NAME & "]" Set rs = New ADODB.Recordset rs.CursorLocation = adUseServer ' rs.CursorLocation = adUseClient rs.CursorType = adOpenForwardOnly rs.LockType = adLockReadOnly rs.Open cmd lRecords = 0 Do Until rs.EOF lRecords = lRecords + 1 v = rs.GetRows(1) Loop ERR_EXIT: If Err.Number <> 0 Then Debug.Print "[" & Err.Source & "]" & "[" & CStr(Err.Number) & "] " & Err.Description End If If Not rs Is Nothing Then If rs.State = adStateOpen Then rs.Close End If Set rs = Nothing End If If Not cmd Is Nothing Then Set cmd.ActiveConnection = Nothing Set cmd = Nothing End If If Not cn Is Nothing Then If cn.State = adStateOpen Then cn.Close End If Set cn = Nothing End If sgStop = Timer Debug.Print "Done. [ " & Format$(sgStop - sgStart, "0.00") & " sec.][ " & CStr(lRecords) & " records.]" End Sub
Scema.ini
[13_tokyo_all_20190930.csv] Format=CSVDelimited CharacterSet=65001 ColNameHeader=False
ADODB.Stream(1行ずつ読み込み)
Public Sub readByAdoStream() Dim strm As ADODB.Stream Dim sLine As String Dim vItems As Variant Dim lRecords As Long Dim i As Long Dim sgStart As Single Dim sgStop As Single sgStart = Timer On Error GoTo ERR_EXIT Set strm = New ADODB.Stream With strm .Type = adTypeText .Charset = "UTF-8" '今回使用したファイルの改行コードは、LF ' .LineSeparator = adCRLF .LineSeparator = adLF .Open .LoadFromFile TARGET_FOLDER & TARGET_NAME Do Until .EOS sLine = .ReadText(adReadLine) vItems = Split(sLine, ",") lRecords = lRecords + 1 Loop .Close End With ERR_EXIT: If Err.Number <> 0 Then Debug.Print "[" & Err.Source & "]" & "[" & CStr(Err.Number) & "] " & Err.Description End If If Not strm Is Nothing Then If strm.State = adStateOpen Then strm.Close End If Set strm = Nothing End If sgStop = Timer Debug.Print "Done. [ " & Format$(sgStop - sgStart, "0.00") & " sec.][ " & CStr(lRecords) & " records.]" End Sub
結果
今回の方法では、結果は以下の通り、
ADODB.Recordset を使った方が圧倒的に速い。
Split 無しの場合で、約20倍
Split 有りの場合で、約6倍
の速度となりました。
あくまで、今回の方法ではです。(重要!)
| 種類 | カーソル ロケーション | Split有無 | 時間(秒) | 備考 |
|---|---|---|---|---|
| Recordset | Server | 無 | 6.76 | |
| 有 | 24.11 | |||
| Client | 無 | 24.10 | ||
| 有 | 34.97 | |||
| Stream | - | 無 | 134.88 | 1回目 |
| 340.79 | 2回目 | |||
| - | 有 | 145.61 | 1回目 | |
| 353.99 | 2回目 |
但し、上記の結果は全てをそのまま鵜呑みには出来ない部分もあります。
- ADODB.Recordset の各フィールドデータと、Splitによる分割をした結果が明らかに異なっている。
これは処理したコードの問題。(こちらにサンプル) - ADODB.Stream の読み込みが、2回目以降が極端に遅くなること。
1項は、1行のデータを要素に分割する手段として、単純に Split しただけのため、
- 「"」で囲まれた要素は、「"」が残る。
- 「"」で囲まれた要素の中に、「,」がある場合、本来1つの要素が複数に分割されてしまった。
ことが原因です。
こちらにもう少し詳しくまとめてあります。
Split 有りのデータについては、参考程度に御覧ください。
2項は根本原因はわかりません。
(予想される要因はありますが、あくまで予想であり、コードで対応できる問題ではなさそうなので・・・)
ただ、改善策はあるので、それは次回とします。
要素分割が正しく行われていなかった・・・
元になるCSVの1行に、こんなデータがありました。1,1000011000005,01,1,2018-04-02,2015-10-05,"国立国会図書館",,101,"東京都","千代田区","永田町1丁目10-1",,13,101,1000014,,,,,,,2015-10-05,1,"National Diet Library","Tokyo","1-10-1,Nagatacho, Chiyoda ku",,"コクリツコッカイトショカン",0
この中に、
"1-10-1,Nagatacho, Chiyoda ku"
「"」で括られた中に、「,」があるので、以下の様になってしまいました。
| ADODB.Recodeset | 1-10-1,Nagatacho, Chiyoda ku | ||
|---|---|---|---|
| ADODB.Stream | "1-10-1 | Nagatacho | Chiyoda ku" |
ADODB.Recorset は、望んだ値が得られています。
一方、ADODB.Stream の方は、何も考えず、Split しただけなので、当然残念な結果になっています。
分割もおかしいし、要素の前後の「"」も残っています。
今回は、読み込み速度の比較がメインなので、このままとします。
上記の対応をしたところで、現時点での速度差が圧倒的なので、無視できる範囲内と想定できるので。
それに、対応すると、差が広がる一方なので・・・
まとめ
それぞれの方法の比較
| 項目 | Recordset | Stream | 備考 |
|---|---|---|---|
| 速度 | 速い | 遅い 2回目以降は特に遅い |
|
| 要素を分割する処理コード | 不要 | 必要 | |
| 改行コード指定 | 不要 | 必要(CRLF以外の場合) | |
| Schema.ini | 必要 | 不要 | |
| 接続文字列 | 必要 少し複雑 |
不要 |
上にも書いたのですが、要素の分割の手間を考えると、
個人的には、ADODB.Recordset の使用がオススメです。
処理速度の点もありますが
- Schema.ini を書く手間
- Split処理を書く手間
「どちらを選択するか?」と言われれば、私は、Schema.ini 書きます。
必要なら、Schema.ini のテンプレート作るツール作ります。(たぶん・・・)
使うデータにも依存するので、どちらを選ぶかは、使う方の判断で・・・
次回予告
今回の結果だけを見ると「ADODB.Recrdset の圧勝」となってしまったのだけれど、色々調べていると
1行読み込みが遅い時の対処法
というのを見つけたので、これについて検証してみます。
また、この対応をしたコードで同じファイルを使って速度を比較してみます。
www.mussyu1204.com
2019/10/23 追記
続編はこちら
z1000s.hatenablog.com
ExcelのVBAで使えるDLLを、C++(Visual Studio 2017)で作る。・・・その3(文字列の受け渡し)
その1、その2と書いたものの
1年以上放置して、いまさらの第3段。
今回は、文字列の受け渡しです。
初めに
初回に書いた設定に要修正箇所があります。
「プロジェクトの設定」の
3.「構成プロパティ」-「全般」-「プロジェクトの既定値」-「文字セット」を
"Unicode 文字セットを使用する"に変更して下さい。
使用する文字範囲が、Shift-JIS の範囲で限定されるような場合には、
マルチ バイト文字セットを使用する
でも良いのですが、Unicode 文字や、JIS 第三水準、第四水準の文字が含まれる可能性が排除できない場合には、
Unicode 文字セットを使用する
としておいた方が、後でトラブルになりにくいと思います。
文字列を受け渡しするためのデータ型
VBAでは、文字列を扱うデータ型は、String です。
これまで、ネットで見つかるコードを見ると、DLL側は、
- char*
- const char*
- wchar_t*
- BSTR
- BSTR*
といった型での受け渡しをしているものが大半を締めていたようです。
しかし、今回の記事では、これらの型を使いません。
使うのは、VARIANT です。
理由は、以下の通りです。
VBA の String は、
ByVal 渡しの場合はバイト文字列 BSTR 構造体へのポインターとして渡されます。
ByRef 渡しの場合はポインターへのポインターとして渡されます。
文字列を格納している VBA の Variant は、
https://docs.microsoft.com/ja-jp/office/client-developer/excel/how-to-access-dlls-in-excel
ByVal 渡しの場合は Unicode ワイド文字文字列 BSTR 構造体へのポインターとして渡されます。
ByRef 渡しの場合はポインターへのポインターとして渡されます。
Excel は、ワイド文字 Unicode 文字列を使用して内部で動作しています。VBA ユーザー定義関数が String 引数を取るように宣言されている場合、Excel は指定した文字列をロケール固有の方法でバイト文字列に変換します。関数に Unicode 文字列を渡す場合、VBA ユーザー定義関数は String 引数の代わりにバリアント型を受け入れる必要があります。その後、DLL 関数は、VBA から バリアント BSTR ワイド文字列を受け入れることができます。
DLL から VBA に Unicode 文字列を返すには、バリアント文字列引数を修正する必要があります。これが機能するには、C/C++ コードでバリアントへのポインターを使用するよう DLL 関数を宣言し、VBA コードで引数を ByRef varg As Variant として宣言する必要があります。古い文字列のメモリを解放し、OLE Bstr 文字列を使用して作成された新しい文字列値は DLL でのみ機能すべきです。
DLL から VBA にバイト文字列を返すには、バイト文字列 BSTR 引数をインプレースで変更する必要があります。これが機能するには、C/C++ コードで BSTR へのポインターへのポインターを使用するよう DLL 関数を宣言し、VBA コードで引数を「ByRef varg As String」として宣言する必要があります。
https://docs.microsoft.com/ja-jp/office/client-developer/excel/how-to-access-dlls-in-excel#variant-and-string-arguments
VARIANT型
VARIANT型は、構造体(VBAでは、Typeステートメントを使って定義するユーザー定義の型と思ってもらえば、とりあえずはOK。厳密に言えば違うんですけど。)で、以下の様になっています。
typedef struct tagVARIANT {
union {
struct {
VARTYPE vt;
WORD wReserved1;
WORD wReserved2;
WORD wReserved3;
union {
LONGLONG llVal;
LONG lVal;
BYTE bVal;
SHORT iVal;
FLOAT fltVal;
DOUBLE dblVal;
VARIANT_BOOL boolVal;
SCODE scode;
VARIANT_BOOL __OBSOLETE__VARIANT_BOOL;
CY cyVal;
DATE date;
BSTR bstrVal;
IUnknown *punkVal;
IDispatch *pdispVal;
SAFEARRAY *parray;
BYTE *pbVal;
SHORT *piVal;
LONG *plVal;
LONGLONG *pllVal;
FLOAT *pfltVal;
DOUBLE *pdblVal;
VARIANT_BOOL *pboolVal;
SCODE *pscode;
CY *pcyVal;
VARIANT_BOOL *__OBSOLETE__VARIANT_PBOOL;
DATE *pdate;
BSTR *pbstrVal;
IUnknown **ppunkVal;
IDispatch **ppdispVal;
SAFEARRAY **pparray;
VARIANT *pvarVal;
PVOID byref;
CHAR cVal;
USHORT uiVal;
ULONG ulVal;
ULONGLONG ullVal;
INT intVal;
UINT uintVal;
DECIMAL *pdecVal;
CHAR *pcVal;
USHORT *puiVal;
ULONG *pulVal;
ULONGLONG *pullVal;
INT *pintVal;
UINT *puintVal;
struct {
PVOID pvRecord;
IRecordInfo *pRecInfo;
} __VARIANT_NAME_4;
} __VARIANT_NAME_3;
} __VARIANT_NAME_2;
DECIMAL decVal;
} __VARIANT_NAME_1;
} VARIANT;結構たくさんの要素があるのですが、この中で、今回大切なのは、以下の3つです。
| データ型 | 変数 | 備考 |
|---|---|---|
| VARTYPE | vt | VARIANTの変数に格納されているデータの型等の情報 |
| BSTR | bstrVal | 文字列データ |
| BSTR* | pbstrVal | 文字列データを指すポインタ |
気が付いた方もいるかもしれませんが、
VARIANTの中に格納される文字列の型は、BSTR型です。
vt
vtに格納される値は、VARENUMの中のいずれかが使用されます。ただし、一部は単独で使用されず、他の値とORを取るフラグとして使用されるものもあります。
VARIANTの変数に、非配列の文字列が格納されている場合、vt は、下表のいずれかの値となります。
| 定義 | 値 | 備考 |
|---|---|---|
| VT_BSTR | 0x0008 | 文字列 |
| VT_BSTR | VT_BYREF | 0x4008 | 文字列(参照) |
bstrVal
vtに、VT_BSTRが設定されている時、bstrValには、文字列が格納されています。pbstrVal
vtに、VT_BSTR | VT_BYREF が設定されている時、pbstrValには、文字列へのポインタが格納されています。以下の2つの違いについては、後述します。
- VT_BSTR
- VT_BSTR | VT_BYREF
関数
DLL側でのVARIANT内部形式の判断
VARIANTとBSTRの変換を行う際に、気をつけなければいけないのが、vt の値です。
文字列が格納されている場合の vt の値は、以下の2つがある事を書きました。
これらは、DLLの関数に渡すVBAの変数の型に依存します。
| vt | VBAの変数の型 | 呼出例 | 備考 |
|---|---|---|---|
| VT_BSTR [ 0x0008 ] | 内部処理形式が Stringの Variant の場合 | Dim v As Variant v = "" Call DllFunc(v) | vがemptyの状態で渡すと、VT_EMPTYとなる |
| VT_BSTR | VT_BYREF [ 0x4008 ] | String の場合 | Dim s As String Call DllFunc(s) |
VARIANTの文字列の変換
VARIANT→BSTR
std::wstring のコンストラクタを使って初期化します。パラメータ v が、VT_BYREF の有無で処理方法が変わってきます。
| vt | 文字列情報が格納されているメンバー | 左記要素に格納されている内容 |
|---|---|---|
| VT_BSTR | v.bstrVal | 文字列 |
| VT_BSTR | VT_BYREF | v.pstrVal | 格納されている文字列を指すポインタ |
コンストラクタの第2引数には、文字列数を渡します。
文字数の取得には、SysStringLen 関数を使用します。
docs.microsoft.com
std::wstring convVstr2Wstr(const VARIANT v) { std::wstring ws; if (v.vt == VT_BSTR) { ws = std::wstring(v.bstrVal, SysStringLen(v.bstrVal)); } else if (v.vt == (VT_BSTR | VT_BYREF)) { ws = std::wstring(*v.pbstrVal, SysStringLen(*v.pbstrVal)); } return ws; }
wstring→VARIANT
VARIANT変数に文字列を設定する場合、以下の手順で行います。- vt に VT_BSTR または、VT_BSTR | VT_BYREF をセットする。
- bstrVal または、pbstrVal に文字列をセットする
VARIANT変数 を vString とする。
vString.vt == VT_BSTR の場合
SysAllocString に、C文字列を指すポインタを渡して、帰ってきた値(BSTR)を直接、vString.bstrVal に代入します。
std::wstring ws(L"設定する文字列"); vString.vt = VT_BSTR ; vString.bstrVal = SysAllocString(ws.c_str()); //以下の方法では、正しく文字列が返らない //BSTR bs = SysAllocString(ws.c_str()); //vString.bstrVal = bs; //SysFreeString(bs);
vt == VT_BSTR | VT_BYREF の場合
一旦、BSTRの変数に対して、SysAllocString を使って文字列を格納します。
上記変数をSysReAllocString に渡し、文字列データをセットします。
SysFreeString を使用して、上記BSTR変数を開放します。
std::wstring ws(L"設定する文字列");
vString.vt = VT_BSTR | VT_BYREF;
BSTR bs = SysAllocString(ws.c_str());
SysReAllocString(vString.pbstrVal, bs);
SysFreeString(bs);
コード
DLL
AccessibleFromVBA.h
AccessibleFromVBA.cpp
AccessibleFromVBA.def
stdafx.h
実行サンプル
SetString実行時

GetStringByParam、GetStringByRetVal実行結果

最後に
文字列はVARIANTで受け渡しですよ!!!
バ・リ・ア・ン・ト
次は配列当たりでしょうか?
では、また1年半後にwww
z1000s.hatenablog.com
z1000s.hatenablog.com
z1000s.hatenablog.com
z1000s.hatenablog.com
z1000s.hatenablog.com
z1000s.hatenablog.com
z1000s.hatenablog.com
プリコンパイル済みヘッダ使わなきゃよかった・・・
【VBA】9桁以上の16進数表記文字列同士のORを求める
昨日、Twitter で、
「16進数のORをとるのにもっと効率のいいやり方ある?」
というやつを見つけました。
16進数のORをとるのにもっと効率のいいやり方ある?
— ささきさん (@sasaki__san) 2019年9月16日
誰かおせーて!#VBA pic.twitter.com/qmQrwBiWti
スマホの小さい画面で見ていたので、
実は細かいところまでは見えなかった(見てなかった?)ので
「単純にLongに変換して、OR とって、Hex で16進表記に戻せばいいのでは」と
返したら、どうも4Byte超相当(9桁以上)の文字列を処理したいらしい。
32bit版では Long(16進数表記で8桁)までしか処理できないので、
8桁ずつループ処理するコードを書いてみました。
なお、Twitter で返したコードを少し変えてあります。
Public Function HexStringOr(ByVal sHexValue1 As String, ByVal sHexValue2 As String) As String Dim lLen1 As Long Dim lLen2 As Long Dim lResultLen As Long Dim lOrgLen As Long Dim sHexW1 As String Dim sHexW2 As String Dim sResult As String Dim lStartPos As Long Dim lHex1 As Long Dim lHex2 As Long Dim lHexW As Long Dim i As Long Const ZERO8 As String = "00000000" '16進文字列判定 If isHexString(sHexValue1) = False Then Exit Function ElseIf isHexString(sHexValue2) = False Then Exit Function End If lLen1 = Len(sHexValue1) lLen2 = Len(sHexValue2) If lLen1 >= lLen2 Then lOrgLen = lLen1 Else lOrgLen = lLen2 End If '8の倍数となる文字列長を求める lResultLen = ((lOrgLen + 7) \ 8) * 8 'ゼロパディング sHexW1 = String$(lResultLen - lLen1, "0") & sHexValue1 sHexW2 = String$(lResultLen - lLen2, "0") & sHexValue2 '結果格納用文字列(ダミー0埋め) sResult = String$(lResultLen, "0") For i = 1 To lResultLen \ 8 '処理先頭位置 lStartPos = 1 + (i - 1) * 8 '8文字抜き出してLongに変換 lHex1 = CLng("&H" & Mid$(sHexW1, lStartPos, 8)) lHex2 = CLng("&H" & Mid$(sHexW2, lStartPos, 8)) lHexW = lHex1 Or lHex2 '結果を格納 Mid$(sResult, lStartPos, 8) = Right$(ZERO8 & Hex(lHexW), 8) Next i '元のデータの桁に合わせてから返す HexStringOr = Right$(sResult, lOrgLen) End Function '16進文字列判定 Private Function isHexString(ByVal sValue As String) As Boolean If Len(sValue) = 0 Then Exit Function End If isHexString = Not sValue Like "*[!0-9a-fA-F]*" End Function
実行サンプル
? HexStringOr("1234567890ABCDEF11","22222222")
1234567890ABEFEF33
? HexStringOr("444444442222222200001122","1111222200008888CCCC3333")
555566662222AAAACCCC3333
? HexStringOr("004444444422222222000011","001111")
004444444422222222001111
「これで(速度的な意味で)効率が良くなったのか?」と聞かれれば、もちろん
「ほとんど変わらないよ!!!」
と言っちゃいます。m(_ _)m
パラメータの文字列が、数千桁とか数万桁なら、こっちの方が若干速いような気がしますけど。
最後に
今回のように、生成される文字列長が予め分かっているような場合には、
都度、文字列を結合するより、
予め、結果の文字列長のダミー文字列を用意しておいて、
それに対して、Midステートメント(Mid関数ではありません)で埋め込んでいったほうが効率的です。
左辺にMidがあるのは、見慣れないかもしれませんが、
覚えておくと便利です。
【VBA】Excelで、ひとつ上の可視セルの値を取得して貼り付けする
Excelでフィルタの適用状態に関わらず、任意のセルの(見た目上の)ひとつ上のセルの値を取得しようというもの。
元ネタはこちら
koroko.hatenablog.com
別の方法で、こちらでも。
infoment.hatenablog.com
両者とは別のアプローチで・・・
目次
抑えておくべき事
Range.Areasオブジェクト
MSのサイトより抜粋。
選択範囲内にある領域 (隣接しているセルのブロック) のコレクションです。
Areasコレクションの各メンバーは、 Range オブジェクトです。 Areasコレクションには、選択範囲内の各セルの不連続な連続した範囲のrangeオブジェクトが1つ含まれています。 選択範囲に領域が1つしか含まれていない場合、 Areasコレクションには、その選択範囲に対応するRangeオブジェクトが1つだけ含まれます。
https://docs.microsoft.com/ja-jp/office/vba/api/excel.areas
Rangeオブジェクトは、Range("A1:C3") といった指定をした場合のように、単一の矩形領域の場合だけでなく
Rrange("A1:C3,D2:F4")とか、Unionメソッドにより複数の矩形領域を纏めてひとつのRangeオブジェクトとして扱ったりする場合もあります。
それらの1個以上の矩形領域をCollectionとして纏められたものが、Range.Areasオブジェクトです。
Itemプロパティ
Areasオブジェクトに含まれているひとつの要素(Rangeオブジェクト)を返すプロパティです。
構文
Areas.Item(Index)
パラメーター
| 名前 | 必須/オプション | データ型 | 説明 |
|---|---|---|---|
| Index | 必須 | Long | オブジェクトのインデックス番号を指定する。 |
省略記法
Areas(Index)
という記述でも同様に処理できます。
Countプロパティ
Areasコレクションに含まれるオブジェクトの数を返すプロパティです。
これにより前述のItemプロパティに指定できるインデックスの上限値がわかります。
構文
Areas.Count
実際の例
領域が分かれることで、Areas.Countが増え、それぞれの要素(Rangeオブジェクト)の情報(下の例ではAddress)を取得できています。

フィルターを使用している場合
フィルター適用前の状態が下図の要なデータで見てみる。

C列のデータを選択した状態

B列をDDで抽出した状態

SpecialCells(xlCellTypeVisible)を指定しないと、非表示のセルも含まれてしまう。
SpecialCells(xlCellTypeVisible)を指定することで、可視セルのみを対象としている。
また、非表示セルが間に入ると、Areasオブジェクト内のItemプロパティで取得する領域が別々になっている。
処理
考え方
- 上記のフィルター適用時の結果から、基準となるセルの上の全てのセルのうち、表示されているセルと、基準のセルをUnionで纏める。
- 基準となるセルは、Unionで纏めたRangeの一番下なので、Areas.Item(Areas.Count) にある。
- Areas.Item(Areas.Count).Rows.Count が1ならば、基準セルのひとつ上のセル(見た目ではなく実際の1行上のセル)は非表示なので、Areas.Item(Areas.Count-1) の一番下のセルが求めるセル。
- Areas.Item(Areas.Count).Rows.Count が2以上なら、基準セルの1行上のセルは表示されているので、基準セルの1行上のセルが求めるセル。
コード
取得データ貼り付け処理
データ取得処理
コードをコピーしたい方へ
いつもの通り、コードはダブルクリックすれば選択できますので・・・
使い方
pasetFromAboveCellsValueをイミディエイトウィンドウから呼ぶなり、
適当なボタンに登録するなり、使いやすいようにして下さい。
実行サンプル

最後に
今回は、前回のやつがあったから気がつけた。
ちょっと満足。
貼り付けだけが目的であれば、プロシージャを分けずに1つにした方が
無駄なコピーが無くせるので、スッキリするかも。
単一のセルだけでなく、複数のセルに対応したのと
データの途中の行でも実行可能なので、少しは使えるか?
【VBA】ExcelのUnionで纏められたRangeの Areas.Count と Areas.Item(N)
- 初めに
- Union メソッド
- Areas.Count と Areas.Item(N)
- 複数の Range がひとつの Areas.Item( N ) に纏められるケース(具体例)
- 対象範囲が同じでも結果が変わる例
- コード(抜粋)
- 最後に
初めに
以前の記事で、Union メソッドで纏められた Range へのアクセス方法を書きました。
z1000s.hatenablog.com
その中で、
今回の場合、
赤で囲まれた範囲がArea(1)
青で囲まれた範囲がArea(2)
となり、
r.Areas(1).Address(False, False)は
B2:D4
r.Areas(2).Address(False, False)は
F3:G4
が返ります。
Unionで指定した順番に返ってくるようです。(そうでないと困ります。)
と書いたのですが、このようにならない場合があることがわかりました。
Union メソッドで、複数のRange を纏めた時、
| 項目 | 値 |
|---|---|
| Areas.Item(N) | 指定した個々の Range |
| Areas.Count | 指定した Range の数 |
となるものと思い込んでいたのですが、そうならない場合があるようです。
また、Union メソッドの実行方法によっては、対象となる範囲が同じでも、Areas.Countや、Areas.Item( N ).Address が変わる場合があることがある事がわかりました。
Union メソッド
まず、改めて Union メソッドについて。
docs.microsoft.com
機能
2 つ以上のセル範囲の集合を返します
構文
expression.Union (Arg1, Arg2, Arg3, Arg4, Arg5, Arg6, Arg7, Arg8, Arg9, Arg10, Arg11, Arg12, Arg13, Arg14, Arg15, Arg16, Arg17, Arg18, Arg19, Arg20, Arg21, Arg22, Arg23, Arg24, Arg25, Arg26, Arg27, Arg28, Arg29, Arg30)
パラメータ
| 名前 | 必須/オプション | データ型 | 説明 |
|---|---|---|---|
| Arg1 | 必須 | Range | |
| Arg2 | 必須 | Range | |
| Arg3~Arg30 | 省略可 | Range | 範囲を指定する |
戻り値
Range
使用例
基本的な使い方は、多分以下の2通りと思われます。
対象となる Range の数が固定の場合は、このような書き方ができます。
Set r = Union(r1, r2, r3, r4)
一方で、対象となる Range が可変の場合や、ループ処理により纏めたいような場合には、こちらの方法が使いやすいと思います。
Set r = Union(r1, r2) Set r = Union(r, r3) Set r = Union(r, r4)
他にも、このような書き方も出来ますが、多分ほとんど使われることはないかと思います。
Set r = Union(Union(Union(r1, r2), r3), r4)
3番目の書き方は、最初の書き方を冗長にしただけのように見えますが、実はそうではありません。
(この件については、後述)
Areas.Count と Areas.Item(N)
実際に返ってくる値
| 項目 | 値 |
|---|---|
| Areas.Item(N) | パラメータで指定した1個以上の Range の纏まり |
| Areas.Count | 1以上 指定した Range の数以下 |
Areas.Item(N)
コレクションから単一のオブジェクトを返します。
https://docs.microsoft.com/ja-jp/office/vba/api/excel.areas.item
MSのサイトには、下記のような記述があります。
コレクションから単一のRangeオブジェクトを取得するのにには、 Areas (index) を使用します。_引数 index_には、area インデックス番号を指定します。 インデックス番号は、領域が選択された順序に対応します。
https://docs.microsoft.com/ja-jp/office/vba/api/excel.areas
基本的には、この通りになるようなのですが、例外があります。
Union メソッドに指定する Range が、以下のような場合、Areas.Item(N) は、複数の Range を纏めた範囲になります。つまり、パラメータで指定された複数の Range が、ひとつの Areas.Item(N) に纏まってしまう場合があります。
「任意の複数の Range の集まりが矩形となる」場合に、
ひとつの Areas.Item(N) として纏まるようです。
その場合、領域が選択された順序と一致しない場合があります。
Areas.Count
コレクションに含まれるオブジェクトの数を表す長整数型 (Long) の値を返します。
https://docs.microsoft.com/ja-jp/office/vba/api/excel.areas.count
ここで注意すべきは、
”コレクションに含まれるオブジェクトの数”
であって、
”パラメータで渡した( Range )オブジェクトの数”
ではないということです。
前述の通り、パラメータで指定した複数の Range が、ひとつの Areas.Item に纏められる場合、Areas.Count は、それに伴い パラメータの Range 数より少なくなることになります。
Range("A1") から Range("A30") までの30個の Range を Uniono で纏めると
Set r = Union( Range("A1"), Range("A2"), ・・・, Range("A30") )
纏められた Range r は、
| Areas.Count | 1 |
| Areas.Item(1).Address | A1:A30 |
| Areas.Address | A1:A30 |
となります。
複数の Range がひとつの Areas.Item( N ) に纏められるケース(具体例)
Union( r1, r2, r3 )
の記述で、纏めてみた結果が下の図です。
下図のA列にアドレス単独で表示されているものは、Union メソッドに渡した Range であり、Union メソッドには、上から順に渡しています。
なお、下図の中の Areas.Address: の後ろに表示されている [ ] で囲まれたそれぞれの部分が Areas.Item( N ) .Address です。
隣接する2個以上の Range が矩形となる場合
Unionに指定するRangeの順番の影響は見られません。

2個以上の Range の一部が重なるが、全体が矩形となる場合
重なっている部分を含め、全体がひとつのAreas.Item( N ) となります。

Range A に、Range B が含まれる場合
サイズが、基準となる(大きい方の)Range以下の Range は無視されています。

対象範囲が同じでも結果が変わる例
記述の違い(実行方法の違い)によるもの
前述の通り、Union メソッドの書き方は、思いついただけで3パターンあります。
同じ Range を、同じ順番でメソッドに渡しても、返ってくる結果が異なる場合を見つけました。
Range r1、r2、r3 を以下の範囲とします。
| 変数 | Range |
|---|---|
| r1 | Range("D4:E5") |
| r2 | Range("D2:E3") |
| r3 | Range("B2:C3") |
これらの範囲を使用して、以下の式が返す結果を比較してみます。
| No. | 式 |
|---|---|
| 1 | Set r = Union(r1, r2, r3) |
| 2 | Set r = Union(r1, r2) Set r = Union(r, r3) |
| 3 | Set r = Union(Union(r1, r2), r3) |
No.1 のみが、他と結果が異なっているのがわかります。
No.1 が、r2 と r3 が纏まっているのに対し、
No.2とNo.3は、r1 と r2 が纏まっています。
| No. | 式 | Areas .Count | Areas .Item(1) .Address | Areas .Item(2) .Address |
|---|---|---|---|---|
| 1 | Set r = Union(r1, r2, r3) | 2 | D4:E5 | B2:E3 |
| 2 | Set r = Union(r1, r2)Set r = Union(r, r3) | 2 | D2:E5 | B2:C3 |
| 3 | Set r = Union(Union(r1, r2), r3) | 2 | D2:E5 | B2:C3 |



No.2、No.3では、順次Unionメソッドで Range を纏めているため、その都度 Areas.Item( N ) が更新されていくため、このような結果になると考えられます。
Union メソッドに渡すパラメータの順番による違い
| 変数 | Range |
|---|---|
| r1 | Range("B2:C3") |
| r2 | Range("D2:E3") |
| r3 | Range("B4:C5") |
として、
Union( Arg1, Arg2, Arg3 ) と呼び出してみました。
| No. | Arg1 | Arg2 | Arg3 |
|---|---|---|---|
| 1 | r1 | r2 | r3 |
| 2 | r3 | r2 | r1 |


No. 2 では、横方向に纏まっています。
コード(抜粋)
コードが欲しい方は、コードをダブルクリックすると、少しだけいいことがあるかもしれません
データ設定、描画処理呼び出し
描画処理
その他
最後に
処理方法によって結果が変わる場合があるのは分かった。
キーワードは、矩形
しかし、Union( r1, r2, ・・・, rn ) の場合の規則性が分からん。
Areas.Item( N ).Address が変わって困るような処理は今の所ないから、
今回はここまでで勘弁してやろう・・・ orz
m(_ _)m
【VBA】偶数判定、奇数判定
主に偶数判定のための私的メモ。
| 判定 | 式 | 結果 | |
|---|---|---|---|
| 偶数の場合 | 奇数の場合 | ||
| 偶数判定 | ( N Eqv 0 ) And 1 | 0 | 1 |
| ( N And 1 ) = 0 | True | False | |
| 奇数判定 | N And 1 | 0 | 1 |
| ( N And 1 ) = 1 | True | False | |
Eqv(XOr の逆パターン)
| 値1 | 値2 | 値1 Eqv 値2 |
|---|---|---|
| False | False | True |
| False | True | False |
| True | False | False |
| True | True | True |
Bit版
| 値1 | 値2 | 値1 Eqv 値2 |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
整数版
| 値1 | 値2 | 値1 Eqv 値2 |
|---|---|---|
| 0 | 0 | -1 (&HFFFF) |
| 0 | 1 | -2 (&HFFFE) |
| 0 | 2 | -3 (&HFFFD) |
| 1 | 0 | -2 (&HFFFE) |
| 2 | 0 | -3 (&HFFFD) |
| &HFFFF | 0 | 0 |
| &HFFFF | 1 | 1 |
| &HFFFF | 2 | 2 |
| &HFFFF | 3 | 3 |
| &HFFFE | 0 | 0 |
| &HFFFE | 1 | 0 |
| &HFFFE | 2 | 3 |
| &HFFFE | 3 | 2 |